大数据的来源主要包括:商业数据、互联网数据、物联网数据。其中,商业数据来源于企业的内部系统(如企业ERP、POS 终端系统、网上支付系统等);互联网数据包括:QQ、微信、微博、网站数据;物联网数据来源于物联网硬件设备(如射频识别装置、全球定位设备、传感器设备、视频监控设备等)。
大数据的数据类型可分为三种:结构化数据、半结构化数据、非结构化数据。其中,结构化数据是关系数据库中的数据,可直接被使用和存储;半结构化数据可通过一定规律存储,如excel表格中的数据;非结构化数据是杂乱无章的,如邮件、网页的文字和图像,需要进行相应的处理才可被存储。
数据采集技术是数据科学的重要组成部分,技术是大数据处理的关键技术之一。常用的采集方法包括两种:ETL工具采集、网页数据采集。
一、ETL工具采集
ETL工具采集是将业务系统的数据通过抽取、清洗转换后加载至数据仓库的过程,目的是将企业中的分散零乱、标准不统一的数据整合,为企业的决策提供分析依据。
ETL采集是商业智能项目的重要环节,目前,互联网公司会采用该技术获取相关数据。
二、网页数据采集
网页数据采集是在互联网中采集数据。网页数据具有多元异构交互性、社会性、突发性、高噪声等特点,非结构化数据比例较高,且数据实时性较强。
目前,网页数据主要通过爬虫采集。爬虫采集需编写爬虫程序或爬虫脚本,爬虫流程是访问一个url(根据网络资料理解:url的中文名称是统一资源定位符,统一资源定位符是互联网资源位置和访问方法的一种简洁的表示,俗称网址),并通过模仿HTTP请求(根据网络资料:HTTP请求是指从客户端到服务器端的请求消息)获取网页。爬虫过程类似于通过浏览器查看并获取网页的信息。
因为Python运行效率较高,且具有较成熟的爬虫框架和网页解析库文件,所以可快速处理网络数据。后文通过Python介绍爬虫(网络爬虫)。
网络爬虫(Web crawler) 是按照一定规则,自动抓取万维网(英文名称为World Wide Web,简称WWW)信息的程序或脚本,一般可分为数据采集,处理,储存三部分。
其中,数据采集是通过模仿HTTP请求获取网页,数据处理是对网页中非结构化的数据进行处理,数据存储包括将新URL放置于URL队列中和将爬取的数据存储至数据存储介质中。


审核编辑:刘清
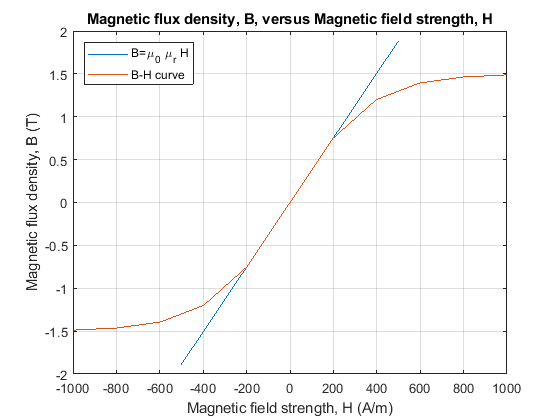 电感器设计流程和见解
电感器设计流程和见解
时间:2026-05-01
 什么是触发器?触发器的作用是什么?
什么是触发器?触发器的作用是什么?
时间:2026-05-01
什么是电源?电源是如何进行分类的?
时间:2026-05-01
电驱动NVH的特点和结构
时间:2026-05-01
什么是霍尔传感器?
时间:2026-05-01
电负性的计算方法
时间:2026-04-30
电导的定义_电导的单位_电导怎么算
时间:2026-04-30
什么是计数器_计数器的作用
时间:2026-04-30
什么是欧姆定律_欧姆定律公式
时间:2026-04-30
RAID是什么?RAID有哪些?
时间:2026-04-30
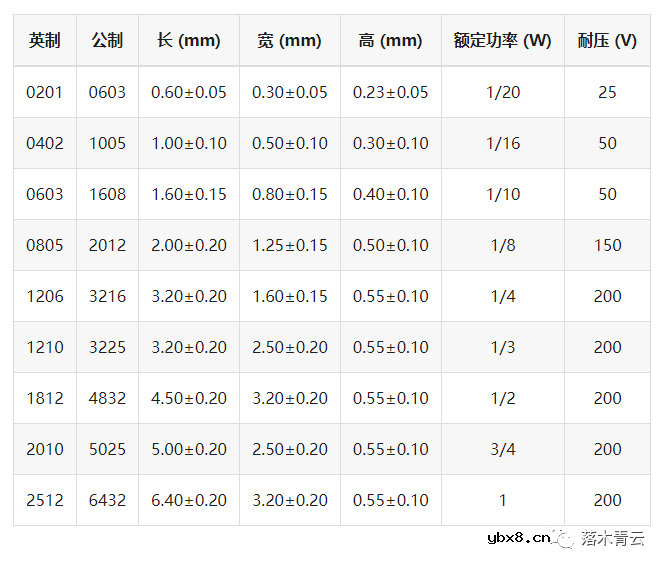 电阻的原理和作用 电阻色环识别图 电路中电...
电阻的原理和作用 电阻色环识别图 电路中电...
时间:2026-03-09
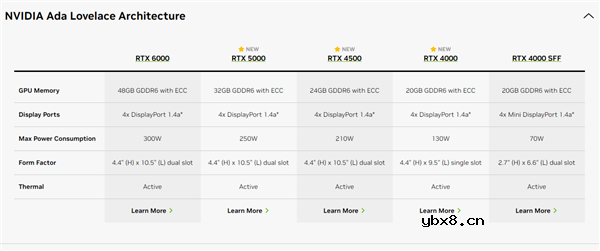 NVIDIA CPU+GPU超级芯片大升级!
NVIDIA CPU+GPU超级芯片大升级!
时间:2026-03-09
什么是室温超导?半导体时代将走向结束?芯...
时间:2026-03-09
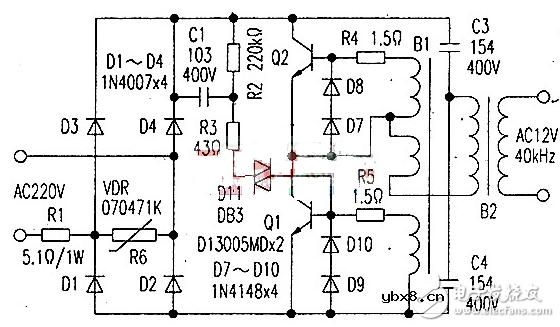 石英灯电子变压器电路原理
石英灯电子变压器电路原理
时间:2026-03-06
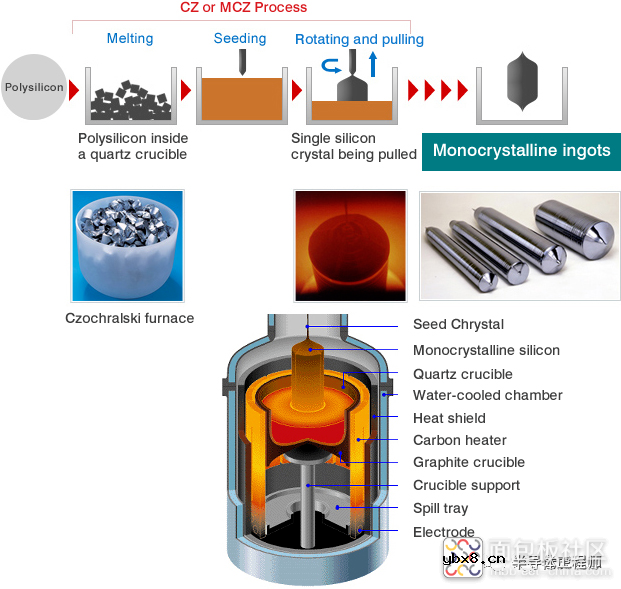 什么是硅片或者晶圆?一文了解半导体硅晶圆
什么是硅片或者晶圆?一文了解半导体硅晶圆
时间:2026-03-09
 半导体光刻工艺 光刻—半导体电路的绘制
半导体光刻工艺 光刻—半导体电路的绘制
时间:2026-03-09
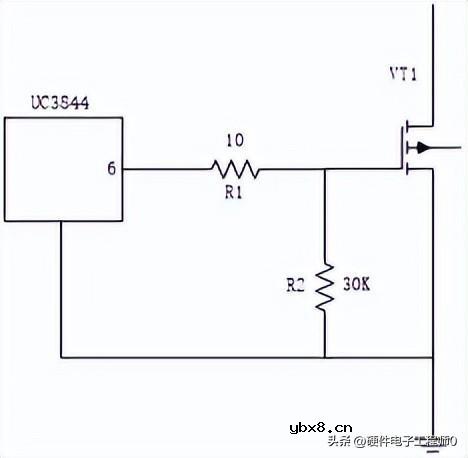 一文详解MOS管驱动电路拓扑的设计
一文详解MOS管驱动电路拓扑的设计
时间:2026-03-09
汽车芯片业应汲取的教训
时间:2026-03-09
压敏电阻型号的含义
时间:2026-03-05
半导体行业之ICT技术简介
时间:2026-03-09