|
1 引言 随着网络和多媒体技术的迅速发展,人们对视频应用提出了新的要求,基于内容的交互编码标准MPEG-4就是适应这一要求而提出来的。MPEG-4视频编码标准面向内容编码,视频数据以基于内容的方式进行压缩、传输、编辑、检索,与以往视频编码标准的主要区别在于对象的概念,输入的视频不再足象素,而是视频对象,以视频对象作为操作的单位实现传统编码的所有功能。视频对象按照时空关系组成的场景,但是场景的前景对象和背景对象得以独立编码,如图1有两种基本的基于视频对象的视频场景的组成方法,每个场景可以由直接从视频序列中分隔的视频对象组成((a)分隔场景),也可以是现有的视频对象进行组合((b)组成场景)。另外也有可能场景是由上述的两种方法结合组成。 MPEG-4视频序列根据视频对象进行解释和处理,这些视频对象是由运动信息,纹理信息和形状信息定义的。MPEG-4视频包通常是基于数据分隔模式编码的,形状信息和运动信息是独立于纹理信息的,是分别传输的。如果纹理信息发生了丢失,利用正确解码的形状信息和运动信息可以进行纹理错误隐藏。而如果形状和运动信息都丢失了,则丢弃整个视频包。
图 1 分隔、组成场景的组成方式 形状信息用Alpha掩模平面来表示,用二值定义(1表示不透明,0表示透明),或用灰度级定义(象素的透明程度介于0~255之间,1表示不透明,0表示透明)。一般都是使用二值掩模平面,视频对象的每个象素位置被定义为完全透明或完全不透明。二值的形状信息对于网络上发生的错误很敏感,并且会很容易发生错误扩散,将会影响连续帧的视频对象解码,现有的纹理和运动信息错误隐藏技术都是在正确获得形状信息的基础上得到的,这说明形状错误隐藏是很必要的。 2 形状错误隐藏技术回顾 MPEG-4编码标准提出了例如插入同步码,数据分割,可逆变长编码等错误隐藏技术。但是这些技术对于现在的通信是不能满足要求的。随着错误隐藏技术的发展,并且形状错误隐藏渐渐引起了很多专家的关注,一些关于形状的错误隐藏技术也相继的被提出。在文中提出了近年来的一些形状错误隐藏技术。 提出的这些技术不外乎是根据图像的自然属性进行错误隐藏的,分空间域的错误隐藏和时间域的错误隐藏,空间域的主要是针对I帧的视频对象形状信息,而时间域的主要是针对P帧和B帧的视频对象的形状信息。时间域的错误隐藏技术也都是基于I帧的形状信息正确解码,所以空间错误隐藏更具有意义。文献提出的方法是利用了自适应马尔可夫域的最大后验估计(MAP)模型对图像进行预先的估计,马尔可夫是为了二值形状信息设计的,参数是根据相邻块的信息自适应确定的。据试验表明此方法能够很精确地恢复形状丢失的形状信息,与中值滤波的方法比较,本文提出的方法能够多恢复20%的丢失信息,获得更好的客观质量。比自适应马尔可夫方法更简单的曲线插值方法,利用Hermite曲线和贝叶斯曲线的特性根据图像的空间连续性来对边界错误块进行错误隐藏。则是利用时间和运动信息进行错误隐藏的。 这些方法都是在解码端对错误块进行修复,并且也取得了很好的效果,但是这些方法针对的错误率是有一定限制的,一旦出现了很严重的错误,很大的丢包率则很难精确地恢复出正确的信息。不仅如此如果丢失的是细节部分利用曲线的特性并不能很精确地恢复信息,这些都对视频对象的解码很不利,并且如果是I帧的形状信息没有恢复,则之后的利用时间域错误隐藏技术也得不到理想的效果。 3 本文的算法 针对此问题本文提出了一个新颖的基于数据隐藏的方法。此方法是收到数字水印技术的启发。数字水印是信息隐藏技术的一种,广泛地用于图像、视频、音频等版权问题,具有透明性、鲁棒性和可证明性,因此数字水印技术也越来越多地运用到内容认证等其他领域。本文就是利用数字水印的特性与形状的错误隐藏技术进行结合,这也是本文的主要创新点。本文主要是针对分隔场景视频的I帧的形状错误隐藏,提出的主要思想是根据的形状信息产生待嵌入的水印信息,而人们关注较少的背景对象则作为嵌入的宿主。 数字水印按照嵌入的过程分为时域/空域水印和频域/变换域水印,一般情况下频域水印比时域水印有更强的鲁棒性与透明性。本文则分别利用这两种不同的实现方法来进行。下面对这两种方法分别进行说明。 3.1 利用频域水印嵌入方法 本文提出的频域的方法是在DCT变换域中的,具体的实施方法如下: (1)首先将二值掩模图像进行采样,缩小到原图像的1/4。根据数字水印技术原理,嵌入的信息量越大则透明性越差。这样做的目的是为了不会太大的影响宿主图像的客观质量。 (2)其次是选择宿主图像,本文是选择背景对象作为宿主,一般视频的背景对象可以转换成RGB三个分量,据研究绿色分量对有损压缩具有很强的顽健性。为了完整地嵌入二值掩模还要对分隔场景的背景对象进行插值,就是利用最简单的水平插值的方法,利用每一行的与零象素相邻的两个非零值的平均值对零值象素位进行填充。填充好的背景图像作为最后的宿主图像。 (3)在上两步的基础上本文选择将水印信息嵌入到宿主图像的频域信息中,将背景图像分隔成2×2的图像块,对每个块进行DCT变换,将水印嵌入到DCT系数的中频系数中,直接用水印的值代替所选择的中频系数。 (4)最后就是水印的提取,二值掩模图像的恢复了。提取则是嵌入的逆过程,直接对接收到的背景图像分割成2×2的图像块,对每个块进行DCT变换,直接提取所选择的中频系数即可,对提取出来的二值图像放大到原来的4倍,这样即得到了恢复的二值掩模图像。 3.2 利用空域水印嵌入方法 本文采用的水印算法是在X.Kang等人提出的算法基础上提出的,首先将作为水印的形状信息则是原掩模二值图像,不做任何改变。方法如下: (1)得到的欲嵌入水印图像应用式(1)进行嵌入。
式中rood为模运算,[α/4,3α/4]是一对最好的参数选择,他保证了0和1都 在具有相等的最大判决范围,使得嵌人水印之后f′与/的差值在[一0.5α,0.5α]之间。当w(m,n)=1时,f(m,n)mod α=3α/4;当ω(m,n)=0时,f(m/n)modα=α/4。因此当提取水印时f*满足f*(m,n)mod α>α/2,那么提取的水印值为ω*(m,n)=l,否则为0。 (2)本文所用的水印嵌入算法是属于盲水印检测,提取过程是不需要原始载体图像的参与。按照公式(2)提取嵌入的水印数据ω*(m,n)。 提取的水印数据ω*(m,n)即为恢复的掩模二值图像。此水印嵌入法将对背景的图像质量会有一定程度的损失,损失程度与嵌入水印时所选的参数α有关。但是水印的提取也与此参数有关。为r能够正确地恢复出水印值,而,f*与/之问的绝对误差(由图像失真引起)必须小于α/4,这里的参数α的适当选择能够很好地折衷水印的透明性与鲁棒性之间的矛盾。α大对图像的损失大,而小不利于水印的鲁棒。根据仿真实验测试,这里a的取值为20。据实验比较,α参数为20时对图像质量的损失还是町以容忍的。 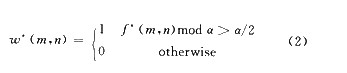 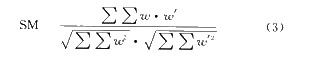 4 仿真结果 对本文提出的算法运用Matlab仿真工具,按照上述的方法对经典视频序列"Foreman"中的第50帧图像进行实验。原视频帧如图2(a)所示,图2(b)为此帧图像MPEG-4编码的形状信息,图2(c)为传输中由于出现错误,接收端得到的错误形状信息。 在第二部分已经阐述了,现有的方法很可能对这种情况不能得到很好的解决。若发生很严重的传输错误或很高的丢包率则形状信息会受到严重的破坏,影响视频对象的正确解码。利用本文提出的两个算法,从接收到的背景绿色分量中提取作为水印的形状信息,本方法的前提是背景的正确传输。图3(a)和图3(b)分别是用频域法嵌入后在解码端正确解码的视频背景对象的效果,以及正确提取恢复的二值掩模图,图3(c)和图3(d)是用空域法嵌入的效果图和提取恢复的二值掩模图。
利用相似性量度来对恢复的掩模图和原掩模图进行比较,来看一下本文的效果如何。相似性量度式为式(3),实验结果表明频域法和空域法恢复的掩模图与原图的相似程度都非常接近1,空域法的效果要比频域法的效果好一些。空域法的背景图像的相似性也比频域法的略好些,频域法嵌入后背景图像信噪比为31.14,空域法嵌入后背景图像信噪比为34.88。比较来说,本文提出的空域法要比频域法的效果更好一些。人们对视频画面的要求往往比静态图片的要求低,并且在基于对象编码中人们对视频背景对象的关注也相对少,所以视频背景对象的视觉损耗也是可以容忍的。
5 结 语 本文提出的算法是与数字水印结合的新颖的形状信息错误隐藏方法,如果接收端的形状信息损失很严重,尤其是I-VOP的形状掩模,若其损坏则会导致随后的VOP预测破坏严重。根据本文提出的两个基于水印的算法则可以获得和原掩模相似度很高的掩模,进而能够得到没有近似、没有损失的对象。但是该算法还是存在一些不足:该方法是基于背景区域没有损失或有一定的丢包率的前提下进行的,并且对背景区域的图像有一定的质量损失。争取找到更鲁棒的嵌入方法和更能忍受的嵌入透明度,这是下一步需要进行的研究工作。 (责任编辑:admin) |



